Why Correlating Data is Bad and What to do About it
Correlating Data
Welcome! This workshop is from Winder.ai. Sign up to receive more free workshops, training and videos.
Correlations between features are bad because you are effectively telling the model that this information is twice more important than everything else. You’re feeding the model the same data twice.
Technically it’s known as multicollinear, which is the generalisation to any number of features that could be correlated.
Generally correlating features will decrease the performance of your model, so we need to find them and remove them.
Again, let’s generate some dummy data for simplicity…
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
X = np.random.randn(100,5)
noise = np.random.randn(100)
X[:,0] = 2*X[:,2] + 3*X[:, 4] + 0.5*noise
The easiest way of spotting correlating features is to generate a scatter matrix. This is an image which plots each feature against each other feature.
# Here, we're plotting a "scatter matrix". I.e. a matrix of scatter plots of each feature.
# Its really useful for spotting dodgy data.
from pandas.plotting import scatter_matrix
df = pd.DataFrame(X)
scatter_matrix(df, alpha=0.2, figsize=(6, 6), diagonal='hist')
plt.show()
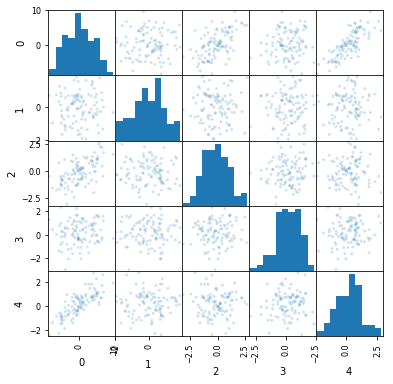
We can see that there is some linearity in the plots. Definitely in the top right.
Again, the simplest thing to do at this stage is manually remove that feature.
del df[4]
scatter_matrix(df, alpha=0.2, figsize=(6, 6), diagonal='hist')
plt.show()
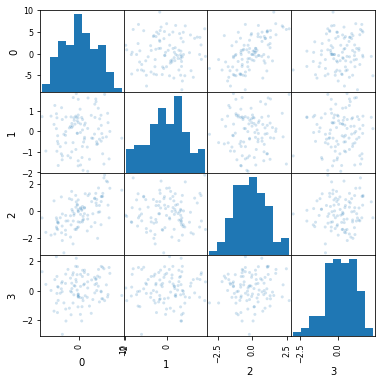
There’s still a little bit of correlation in the second feature, but it’s not huge. Try scoring your model with and without this feature.
We could perform this process in a more quantitative manner using eigenvectors and eigenvalues to spot the correlation, but that’s a bit too complex to consider at this point.